怎样使用FontCreator的ScanaFont生成新字库
FontCreator的ScanaFont使用起来颇为简单。一共只有3步。
下载Scanahand 。迄今为止,3.0版都是浏览版,未见破解版。1.0版可以正常使用。
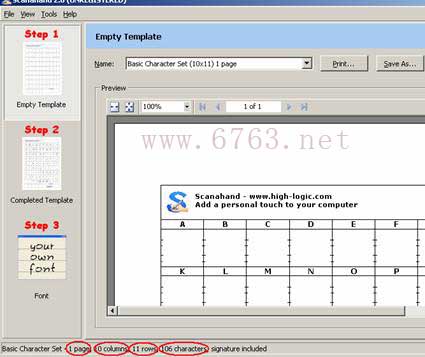
安装后启动ScanaFont,如图:
首先你得打印一页Scanahand的标准页(按打印键)。直接打印在A4纸上即可。
字符务必在标准页的空格内书写。
上边写得十分清楚,单页制作的数量为:每页10列、11行,一共106个字符或标点 如果你书写的字符比较多,你最好按照Unicode(或目标字库)的顺序进行。
准备好所有的字稿之后,点击第二部,如图:

你可以直接用扫描仪将图像扫进来,也可以统一扫描后载入(Load)进来。但是无论如何,都必须使用Scanahand标准页,否则程序会报错:
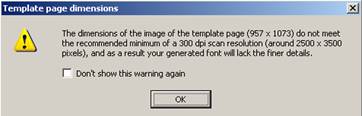
如果你能够使用标准稿纸,使用300dpi进行扫描,那么下面进入第三步,点按Generate之后,程序自动对扫描的图像当中的字符进行分割和识别。如图:
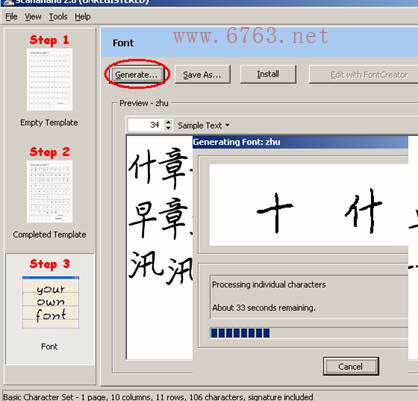
识别完毕后,可以另存为ttf文件。
由于单页纸不可能写上全部汉字6763个字符,所以当然得分多次进行(6763÷110=最少得62页)。最后在FontCreator里面合成。
十分遗憾,如果你使用的是毛笔,那么除了小楷之外,恐怕不易处理。至少得翻拍、放大、缩小等等折腾几个回合。
总之,FontCreator的Scanahand局限比较大,使用起来较之FontLAB的Scanfont要差一些。 至少,scanahand不能直接命名Unicode编码吧?如果每一页都得从abcd开始,不免麻烦。另外,找scanahand的破解版也颇费周折。此外,最重要的,字库扫描,讲究一个“步长”定义。scanfont的步长定义完整而详尽,scanahand则完全没有,这不能不说是一个遗憾。
无论什么样的拼音文字的字库扫描编辑程序,都有一个共同的问题,就是字符图像在em方阵中位置和调谐的问题。
因为拼音文字都是横向顺序排列的。如果想对齐(人家的书法史上也都是这样做的),就以“基线(BaseLine)”为准。而汉字不是这样,汉字需要的是居中对齐的。BaseLine对汉字意义不大。此外还有一点,汉字讲究个“动态关系”。这个拼音文字没有提供现成的工具。所以,在你庆幸使用了不要钱的字库制作程序的时候,一定会感到最大的难点是对汉字的调谐工作。你很难、很不方便调谐汉字在em方阵中的上下、左右、大小、肥瘦、角度等等。
因此我们创作了《编览器》对汉字字库的编辑校对进行。
